INSIGHTS XGBoost gone wild — Predicting returns with extreme gradient boosting

ABOUT YOU TECH
This article describes what kind of machine learning is used in one of Germany’s leading fashion e-Commerce’s to help with decision making and a brief explanation of the techniques used.
One of the decisions ABOUT YOU made very early was to give customers a full 100-day return policy. This way each customer has enough time to decide whether or not the person likes the outfit that was purchased. If a customer is not fully pleased with the product (i.e. bad fit, or different than expected) he can return the product without any repercussions.
Though this is awesome for customers it makes calculating the actual revenue notoriously hard since all products that are bought today could actually be returned somewhere inside the 100-day period. But usually people get very nervous if they have to make decisions on future spendings while basically being blind for our actual current revenue (and they should be!). To reduce the blindness we at the the Business Intelligence Unit at ABOUT YOU came up with a solution to help make decisions on the current events and not on the events that happened 100 days ago.
So of course there is a myriad of solutions for this problem, but the system we needed had to have the following characteristics:
- Interpretability — The prediction needed to be transparent in order to improve on the trust that has to be given to the prediction
- Accuracy — Estimating returns has a high leverage on revenue, so the overall Error of the prediction should be as minimal as possible
- Maintainability — The created predictor should be easily maintainable for everyone working in the field
- Performance — In an ever growing e-commerce the solution needs to cope with an increasing amount of data while not losing performance i.e. the time needed to predict samples.
So what to do then?
One of the advantages of working in an e-Commerce is that we have a ton of examples of already bought products for which we know whether or not they have been returned.To build some kind of prediction, we extracted several product purchase details from previous purchases and mapped those to the outcome of the purchase (product was returned / product was not returned).
Now, to build a model that can accurately predict whether or not a product will be returned we need something that can take a bunch of product details and map these details to the correct outcome (product returned/not returned). Additionally it should use the knowledge gained from previous examples to predict new examples with product details it has never seen. To build such a model we decided to use methods coming from machine learning , in specific terms: supervised learning. A supervised learner needs a dataset containing the input X and the corresponding output Y and tries to map all inputs from X to the output while minimizing the overall error of misclassification. To give an example of a ‘supervised learner’ you can think of a simple regression task for example (i.e. predicting sale prices of houses based on the total amount of square metre floor space). The input (area of a house in square meters) is mapped to a corresponding output (in this case the sale price of the house). The people at R2D3 made a fantastic visual introduction to machine-learning. If you’re interested in a more visual approach to machine-learning (especially decision trees) you should check out.
For our problem a simple regression wouldn’t be sufficient, but there are several supervised learning algorithms as an alternative. The algorithm we decided upon is described as gradient tree boosting using decision trees as a base learner.
Decision Trees
Decision trees are one of the more basic forms of supervised learner. They can be used in multiple scenarios either for predicting a single variable (i.E. housing prices), predicting a binary variable (something will happen or will not) or predicting one out of several classes. All of these scenarios need an input dataset X and the corresponding output Y [In our case either one (product was returned) or zero (product was not returned)].
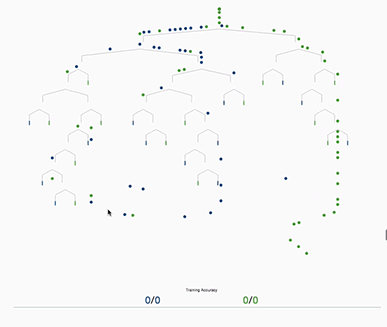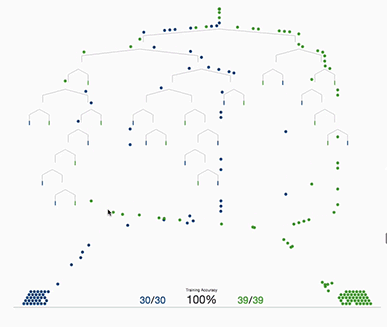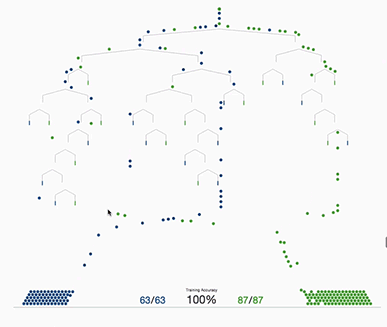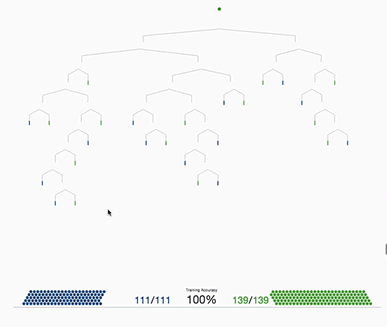
Based on the input dataset a decision tree tries to come up with rules that help it classify the input X. Usually a rule is defined as a condition that a certain feature in our input dataset is greater or smaller than some number (see below). Multiple of these rules are combined by a logical AND, which makes up a decision tree.
These decision-rules are built by finding some value, that minimizes the uncertainty (or entropy) in the subsets created by the rule. This means it tries to create mostly ‘clean’ subsets, which for example in the case of binary classification only (or mostly) contain values from one class. More generally in information-theory, entropy describes the amount of bits needed to encode a subset, if there are only positive or only negative samples in a subset the information entropy is equal to zero, meaning zero bits are needed to encode this information. If your created subset contains 50% positive and 50% negative samples, you need one bit to encode that subset. But this is only an interpretation since entropy in most cases is not bound to be one or zero, and entropy can be something like 0.5 which makes it difficult to use the bit interpretation since there are no ‘half-bits’ but it makes the idea a little bit easier to understand.
Decision trees in itselves are very nice but in most cases their accuracy is not sufficient for highly accurate predictions so people developed extensions to this approach. The most common extension-technique for decision trees is ensembling. Ensembling describes the act of combining multiple weak classifier into one strong classifier. With decision trees there are two very common ensembling techniques: random forests and gradient tree boosting.
Random forests
Random forests extend the idea of decision trees with two major ideas. The first extension used is a so called ‘tree-bagging’ algorithm. Tree bagging is a technique that trains multiple decision trees based on random samples from your original dataset and then averages the prediction of all trained decision trees. The second technique that is used for random forest trees is called feature bagging or random subspace method. Feature bagging describes a very similar approach to tree-bagging, the only difference between these two is that tree bagging samples data points whereas feature bagging samples features. So in feature bagging multiple trees are trained on a subspace of the features present in the dataset and the resulting predictions from all resulting trees are combined. A random forest combines both of these techniques and averages all trees again.
Gradient tree boosting
Gradient tree boosting uses a different approach. Instead of creating multiple trees and averaging the predictions, gradient tree boosting creates one decision tree at a time. It starts with a simple decision tree, after the tree has been trained, it is recorded for which samples the tree makes classification mistakes. After that a second tree is trained to predict, how wrong the preceding tree classified an input and tries to correct the predictions of the first tree. After that another tree is constructed that again tries to estimate the error of its preceding tree and so on.
You can think of Random Forests as a group of people that is trying to make a decision on a certain topic. Each individual of the group has a certain subspace of knowledge and each person makes a decision based on his knowledge, after everybody made a decision the majority vote of the group is the final decision.
For gradient tree boosting you can imagine a group of people (or dogs) where each person/dog tries to correct the mistakes made by the individual that previously made a choice and thus trying to achieve the best possible solution for the problem.

The only drawback of regular gradient boosted trees vs random forests is that — out of the box — random forests are very easy to parallelize, since each tree can be trained simultaneously on a different subset of the dataset. The recursive nature of the gradient boosted trees makes this a little bit more tricky though they generally tend to produce higher accuracy.
XGBoost
To overcome that drawback Tianqi Chen and Carlos Guestrin developed a scalable alternative of gradient tree boosting (“XGBoost: A Scalable Tree Boosting System” ), which was the main machine learning technique used in a Kaggle Challenge to detect the Higgs-Boson and became widely known after that success. The XGBoost library is open source and a great way to create massive and very robust gradient boosting trees that can train on hundreds of features in mere seconds or minutes.
As you’re probably guessing we decided to use XGBoost as the core component of the return prediction due to its robustness and speed. Doing so, we’re able to process ~12 million rows in a matter of minutes with a very high accuracy in predicting whether or not a product will be returned. Also since the company is constantly growing, and the amount of daily processed orders is steadily increasing since 2013, using XGBoost helps to cope with the ever growing amount of data. The library itself is very easy to use and offers a lot of visualizations which come in very handy if you’re trying to explain to non-techies how this machine works simply by showing an example of a simple tree and explaining what rules are used in some of the trees.
To sum it up, Xgboost is awesome and the (basic) idea behind it is very easy to explain and communicate which makes it, in my honest opinion, one of the best machine learning frameworks. Hooray XGBoost!
About the Author: Basti Thiede has worked at ABOUT YOU’s Business Intelligence Unit.
More articles

ABOUT YOU TECH
ABOUT YOU TECH