
INSIGHTS From Prototype to Production

ABOUT YOU TECH
Adapting workflows to fit teams and their products — Christian Flack
The “greenfield”
Whenever we as developers get tasked with building something new instead of adapting, improving, or maintaining an existing application, we get sparkles in our eyes. A greenfield project is something like the holy grail, basically what every developer started out with, and presumably why they chose this profession. Greenfield projects however, do change color rather quickly. As the team responsible for this project, you’ll have to adapt the way you work to meet the requirements of an application that is steadily transitioning from prototype to something that is actually production ready.
Why we love the untrodden path
Being a software developer is, at its core, about finding the best path to a certain destination. That destination as a metaphor might be — “Make a purchase button lead to a purchase page”, or something like — “Enable the application’s user to upload their holiday pictures and allow them to decide who has access to each individual picture”. While the destination matters of course, the preconditions make all the difference, which is why we love the greenfield as much as we do. We get to choose the path to the destination without having to take an existing codebase into account. We are not held back by legacy code. We can lay a foundation for an application that will stand the test of time, be easily extendable, a joy to maintain, and where no future developer will ever want to git blame to find out who’s responsible for shitty code.
Idea to working prototype
When you start working on something new you have a lot of decisions to make. Depending on the specific situation you are in these decisions might range from which programming language is used to deciding upon a database that is the best fit for your project, and whether existing packages can be used for functionality “X” or if a custom solution is necessary. All these decisions are incredibly important and it’s a lot of fun to check out all the alternatives but at some point the decisions are made, after which we must live with whatever the consequences are.
The quality of the decisions you make in that early stage of the project highly depend on the clarity of vision as it relates to what the project should one day become. The less defined the goal of your project, the more you have to factor in uncertainty, which you will quickly discover when your prototype is being used for the first time by its intended audience with actual, real-life data.
Where we ended up vs. where we wanted to go
So, the product of several weeks of carefully made decisions, long hours of coding and a lot of hard work got deployed to production and actual people are starting to use it. Great…right?
Until the bug reports come in. No matter how carefully you work and how much time you spend on staging to make sure everything works as it should, the real world will always prove more complicated, bugs will come in, and likely never stop. That’s new. So far, you did your job and built something according to given specifications, which was then tested by QA or other developers. Some mistakes were found and corrected, but now you have to deal with things in a different manner. Most of the time, a workflow like the one described above will still be applicable and no immediate action will be required. Sometimes however, immediate action is exactly what you need.
Dealing with the paths that can lead you off a cliff
When you are working on a prototype and you break it, nothing really bad actually happens. Sure, your development workflow might stumble a bit if develop gets some code that does not actually work, but it’s all relatively painless because no one uses that code anyway, so you just create a bug ticket put it at the top of your backlog and work on it as soon as you can. But that is not feasible if you’re working with customer data in the real world or if a feature your products’ users need simply does not work. You need a way to expedite these sorts of tasks, you need a fastlane and a process to deal with tasks in it.

Depending on your team setup, how you deal with fixing broken things on production will of course differ. For us, we are a four person team, where each team member has the background and ability to handle any type of task that comes in, it’s relatively simple. Other teams have different setups, like a split of responsibilities with dedicated backend and frontend developers, where not everyone can handle every type of blocker that comes in. Regardless of who, when a fastlane task should be handled is fairly straightforward: Now

How to bridge the gap
When our project was in prototype mode and there was no production environment for it yet, we used feature branches to control what goes to the base of our work — the develop branch. That will not do if you need to control more states of your project once it reached production. Keeping with the approach described in git flow, we ended up using develop as basis of current feature development and using the master branch to maintain what is actually on our production systems at any given time. This means that any fix for a critical bug discovered on production will also have to be done on a branch originating from that very same master branch.
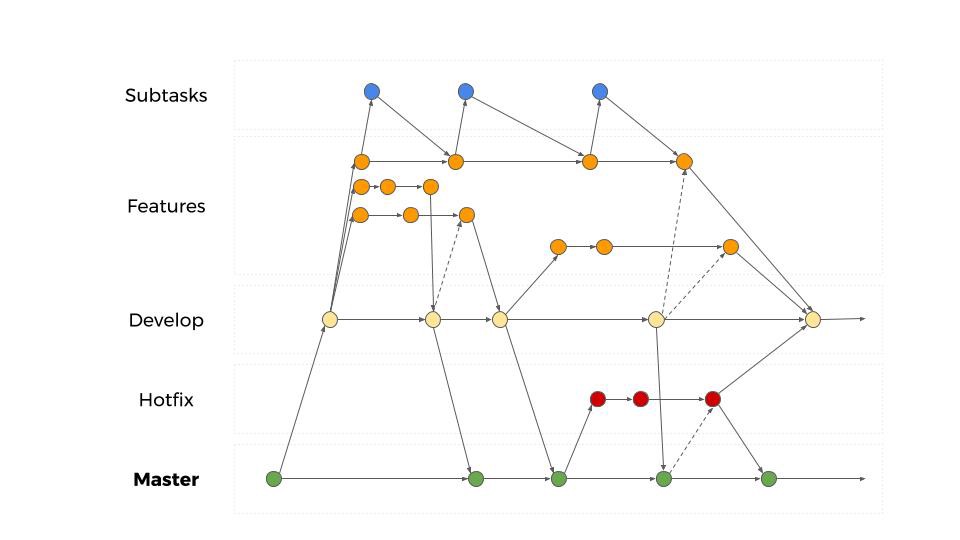
When the destination path is too long
Comparing working on a prototype that just went to production with a more mature project that has been used for a couple of months, or even years, differs in that you‘ll still end up with tasks that break the scope of a standard sprint, because it still contains a rather large amount of groundwork. In our team we put a lot of effort and value in pull requests to make sure no code ever reaches develop and master that has not been reviewed by another developer. This however gets tedious when the feature needs hundreds of lines of code to get completed.
What our team decided to do to alleviate this goes against the classic git-flow of working, but so far, it seems to work pretty well for us:
When we notice during planning that a feature will require an above average amount of work and contains more than a couple subtasks (that may be worked on independently) we create a feature branch as a basis for all work that needs to be done to complete the desired functionality. We then go ahead and create subtask branches based on that feature branch for all subtasks required. To make sure all written code gets reviewed without having to check all code in one review, a task which would take more than a day, we actually create pull request for each subtask to be merged into the feature branch it was based on. That way, the amount of code per review is still manageable, and we can make sure that even large tasks get reviewed with the appropriate amount of vigilance. In the final step, when all subtasks have been completed, another pull request is created to merge the feature branch back to develop. During this last step we make sure that the implementations of each subtask work well with each other and that the desired goal was actually reached.
Where we were and where we’re headed
Working on prototypes is great for every developer involved and holds a lot of promise. However, it will also require you to adapt your workflow when your prototype starts being used by the desired end-users. During prototype creation you rarely have a need for a bug-specific workflow, but that all changes once your code starts being deployed to a production environment.
You’ll have to define how you want to deal with blockers on production, which led us to start using a fastlane in our ticketing systems and using the master branch as a basis for all hotfixes. Additionally, working on a rather fresh product means you will also have to deal with larger tasks that require a lot of groundwork, in addition to the actual feature implementation. What that meant for our team was potentially gigantic pull requests that would take too much time or were more prone to human error in the form of overlooked bugs. In our case, the solution for that particular problem was to split large tasks into subtasks that get implemented on branches of their own, then merge them into a feature branch which will hold all necessary code for the complete functionality.
Looking forward I believe it is safe to say that the workflow we use in our team will change again soon enough. A lot of these definitions were made after we noticed that the workflows we used during the prototype phase would not hold after bringing our project to the production level. Our product is still very young compared to others in our company, and the team itself has only existed for about half a year. Changes are a pivotal part of development work and workflows especially need to adapt to both the team and their products to keep output, quality, and developer satisfaction as high as possible.
More articles

ABOUT CREATIVITY: Our First Hackathon
March 31st, 2017 — Devs team up to flex their collective minds and solve interesting problems.
ABOUT YOU TECH
